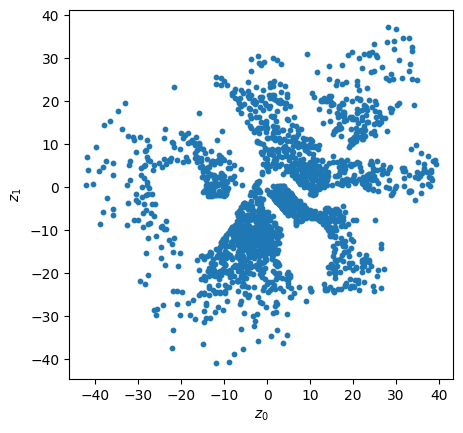
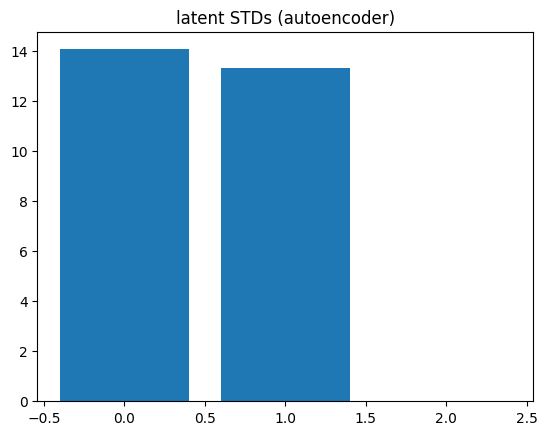
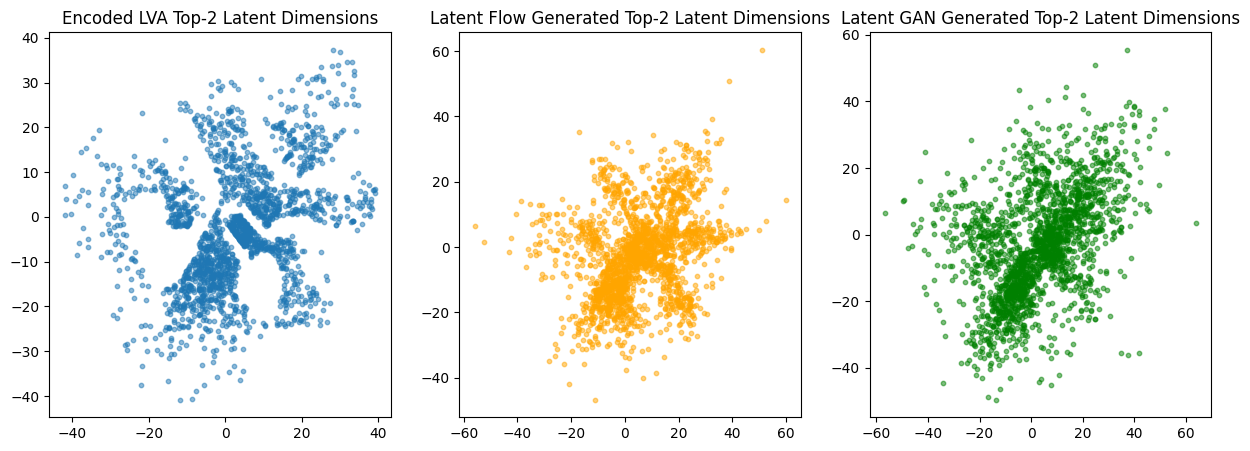
# Convert to numpy for Plotly
X_np = X.detach().cpu().numpy()
#samples_data_np = samples_data.detach().cpu().numpy() if hasattr(samples_data, 'detach') else np.array(samples_data)
decoded_latent_np = decoded_latent.detach().cpu().numpy() if hasattr(decoded_latent, 'detach') else np.array(decoded_latent)
# Build interactive Plotly 6-panel figure
fig = make_subplots(rows=3, cols=2,
specs=[[{'type':'scene'},{'type':'scene'}], [{'type':'scene'},{'type':'scene'}], [{'type':'scene'},{'type':'scene'}]],
subplot_titles=('Ground truth (3D)', 'Autoencoder Reconstruction', 'Data-space flow (3D)', 'Data-space GAN (2D)', 'Latent Flow → decoded (3D)','Latent GAN → decoded (3D)'))
# Ground truth
fig.add_trace(go.Scatter3d(x=X_np[:,0], y=X_np[:,1], z=X_np[:,2],
mode='markers', marker=dict(size=3, color=color, colorscale='Viridis', opacity=0.8)),
row=1, col=1)
# AE Reconstruction
fig.add_trace(go.Scatter3d(x=X_np[:,0], y=X_np[:,1], z=X_np[:,2],
mode='markers', marker=dict(size=3, color='rgba(50,50,50,0.4)'),
name='Original'),
row=1,col=2)
fig.add_trace(go.Scatter3d(x=X_rec[:,0], y=X_rec[:,1], z=X_rec[:,2],
mode='markers', marker=dict(size=3, color='red'),
name='Reconstructed'),
row=1,col=2)
#fig.update_layout(title='AE Reconstruction: Original vs Reconstructed (Plotly)', height=600)
# Data-space samples
fig.add_trace(go.Scatter3d(x=samples_flow_data_np[:,0], y=samples_flow_data_np[:,1], z=samples_flow_data_np[:,2],
mode='markers', marker=dict(size=3, color=samples_flow_data_np[:,0], colorscale='Viridis', opacity=0.8)),
row=2, col=1)
# GAN Samples in Data Space
fig.add_trace(go.Scatter3d(x=samples_gan_data_np[:,0], y=samples_gan_data_np[:,1], z=samples_gan_data_np[:,2],
mode='markers', marker=dict(size=3, color=samples_gan_data_np[:,0], colorscale='Viridis', opacity=0.8)),
row=2, col=2)
# Decoded latent flow samples (color by first latent coordinate)
latent_color_flow = samples_latent_flow.numpy()[:, 0] if hasattr(samples_latent_flow, 'numpy') and samples_latent_flow.ndim==2 else None
fig.add_trace(go.Scatter3d(x=decoded_latent_np[:,0], y=decoded_latent_np[:,1], z=decoded_latent_np[:,2],
mode='markers', marker=dict(size=3, color=latent_color_flow, colorscale='Viridis', opacity=0.8)),
row=3, col=1)
# Decoded latent GAN samples (color by first latent coordinate)
latent_color_gan = samples_latent_gan.detach().cpu().numpy()[:,0] if hasattr(samples_latent_gan, 'detach') and samples_latent_gan.ndim==2 else None
decoded_gan_latent_np = decoded_gan_latent.detach().cpu().numpy() if hasattr(decoded_gan_latent, 'detach') else np.array(decoded_gan_latent)
fig.add_trace(go.Scatter3d(x=decoded_gan_latent_np[:,0], y=decoded_gan_latent_np[:,1], z=decoded_gan_latent_np[:,2],
mode='markers', marker=dict(size=3, color=latent_color_gan, colorscale='Viridis', opacity=0.8)),
row=3, col=2)
# set same camera for consistency
camera = dict(eye=dict(x=1.2, y=1.2, z=0.6))
fig.update_scenes(camera=camera)
fig.update_layout(height=1800, width=1200, showlegend=False, title_text='Comparing Data-Space vs Latent-Space Flow (interactive)')
fig.show()